Datenmodelierung
Das Ziel einer Datenbank ist es meistens, die echten Informationen aus einer Umgebung (z.B. Geschäft) möglichst exakt darzustellen. Diesen Vorgang nennt man Datenmodelierung. Es geht also darum festzulegen, welche Informationen wir festhalten wollen.
Doch bevor wir uns diesen Überlegungen zuwenden schauen wir noch ganz kurz darauf, mit was wir eigentlich arbeiten.
Relationale Datenbanken - Tabellen mit Beziehungen
Es wird dich freuen zu hören, dass Datenbanken (stark vereinfacht) nichts anderes sind als Sammlungen von Tabellen. Also Zeilen und Spalten, wie du es schon von Excel-Tabellen kennst. Das Kern-Prinzip hinter Datenbanken sind so genannte relationale Tabellen. Also Tabellen, welche sich auf einander beziehen.
Das klingt vielleicht etwas kompliziert, ist aber total logisch: Denk noch einmal kurz an unser Strick-Geschäft. Angenommen, wir wollen unsere Bestellungen in einer Tabelle verwalten. Dazu gehören auch die Kundendaten zu jeder Bestellung. Das könnte so aussehen:
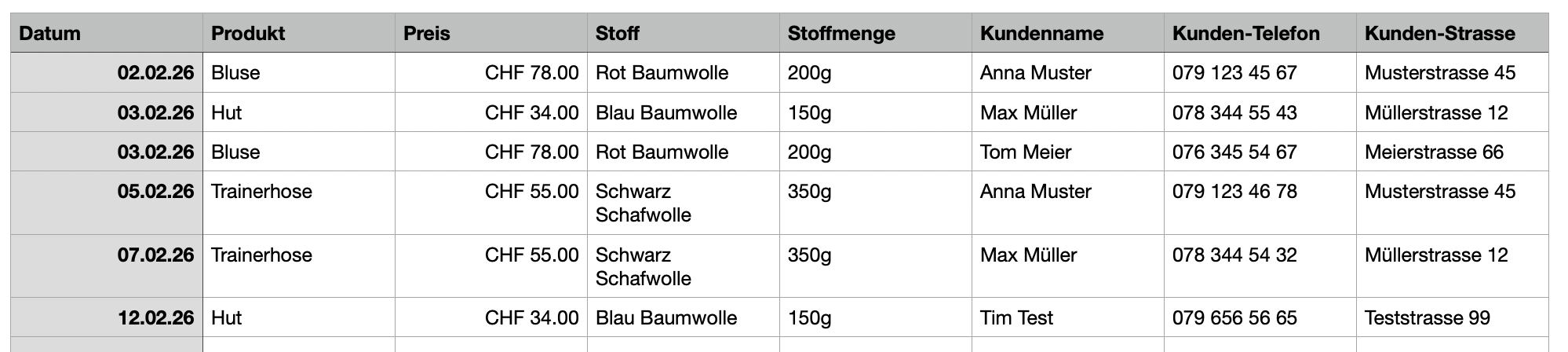
Hoffentlich erkennst auch du einige der Probleme mit dieser Tabelle (um nur ein paar zu nennen):
- Viele Daten sind doppelt vorhanden (und müssen doppelt angepasst werden falls sich etwas ändert -> Chaos)
- In echt kommen vermutlich noch viele Informationen dazu. Das führt zu einer sehr grossen Anzahl Spalten.
Wesentlich sinnvoller wäre es doch, diese Informationen in mehrere Tabellen aufzuteilen, z.B. Bestellungen und Kund:innen:
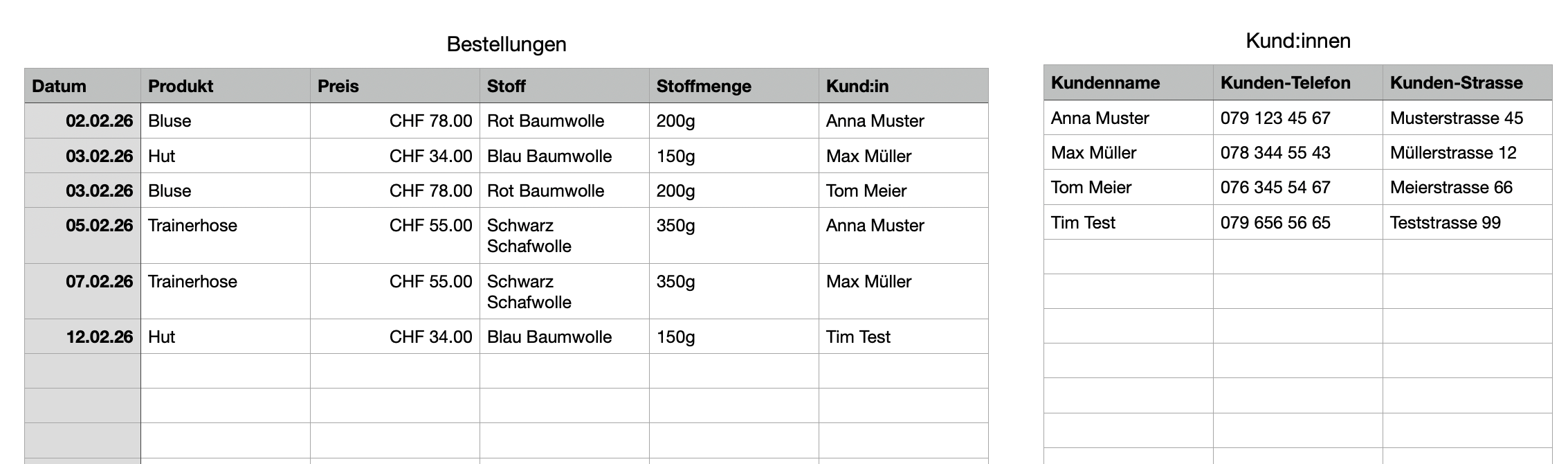
In diesem Beispiel haben wir nun also eine Beziehung (Relation) zwischen der Tabellen Bestellungen und Kund:innen. Jede Bestellung hat einen Kunden.
Solche Beziehungen gibt es in jeder Art von datenbankbasierten System.
- Schule: Schüler:innen besuchen Kurse, Lehrpersonen unterrichten Kurse
- Social Media: Nutzende erstellen Posts. Posts haben Kommentare.
- Gesundheitswesen: Patient:innen buchen Termine. Ärzt:innen erstellen Notizen zu Patient:innen
- ...
Die Aufgabe einer/eines Datenbank-Ingenieurs ist es nun beim Planen eines Systems diese Beziehungen möglichst exakt zu erfassen. Dafür sind oftmals viele Gespräche mit zukünftigen Nutzer:innen erforderlich. Wenn dieser Schritt nicht richtig gemacht wird können in grossen Informatik-Projekten schnell Millionen von Franken in den Sand gesetzt werden, da eine nachträgliche Anpassung oftmals sehr aufwendig ist.
Auszug aus der Geschichte
Der Erfinder dieses relationalen Modells (also der Idee von Tabellen mit Beziehungen) ist E.F. Codd. In seinem wissenschaftlichen Paper von 1970 A relational model of data for large shared data banks beschreibt er die Konzeptuelle Idee.
Interessant dabei ist: Im Abstract (wichtigster Teil des Papers) beschreibt er als wichtigste Neuerung gegenüber anderen, existierenden Lösungen den Fakt, dass bei seinem System die Benutzer:innen nichts über die interne Strukturierung der Daten wissen müssen. Nutzer:innen müssen nur die Tabellen und die Beziehungen kennen. Mit anderen damaligen Systemen musste man als Benutzer:in sehr viel technische Details kennen, um mit den Daten interagieren zu können. Das setzte viel technisches Know-How voraus.
Das neue, relationale Modell von Cobb ermöglichte die Nutzung von Datenbanken für allerlei Zwecke ausserhalb der Kern-Informatik, wie z.B. in der Forschungs und machte Datenbanken für viel mehr Menschen zugänglich.
Die wichtigsten Konzepte in relationalen Datenbanken
Um diese Arten von Beziehungen darzustellen, sind ein paar wenige Schlüsselkonzepte notwendig.
Primäre Schlüssel (Primary Keys) 🔑
Jeder Eintrag in einer Datenbank-Tabelle muss eindeutig erkannt werden. Das System muss schliesslich deine Nutzerdaten eindeutig erkennen können, um sie dir zuverlässig anzuzeigen und damit du beim nächsten Login nicht auf einmal die Daten von jemand anderem siehst. Nur, wie macht man das? Wie erkennt man eine Bestellung eindeutig unter tausenden von Bestellungen?
Das macht der Primary Key. Eine Spalte in der Tabelle wird als Primary Key festgelegt. Jeder Eintrag (jede Zeile) muss dann in dieser Spalte einen eindeutigen Wert haben - Sonst besteht ja wieder Verwechslungsgefahr. Wenn wir uns noch einmal die Kund:innen-Tabelle von oben anschauen, welche Spalte wäre dafür geeignet? Überlege es dir kurz, bevor du weiterliest.
Lösung
Intuitiv könnte man meinen, die Spalte Kundenname wäre gut geeignet. Nun ist es aber bei einem grösseren Geschäft schnell möglich, dass zwei Kund:innen den gleichen Namen haben.
Vielleicht haben unsere Kund:innen ja noch einen Benutzernamen (wie z.B. bei Instagram) oder eine E-Mail Adresse, die/der eindeutig ist. Diese wären dann besser geeignet. In der Realität wird oft etwas gemacht, dass du von deiner Identitätskarte kennst: Jeder Eintrag (Im Beispiel ID -> jede:r CH Bürger:in) bekommt eine eindeutige Kennzeichnung, die automatisch erstellt wird. Also z.B. so:
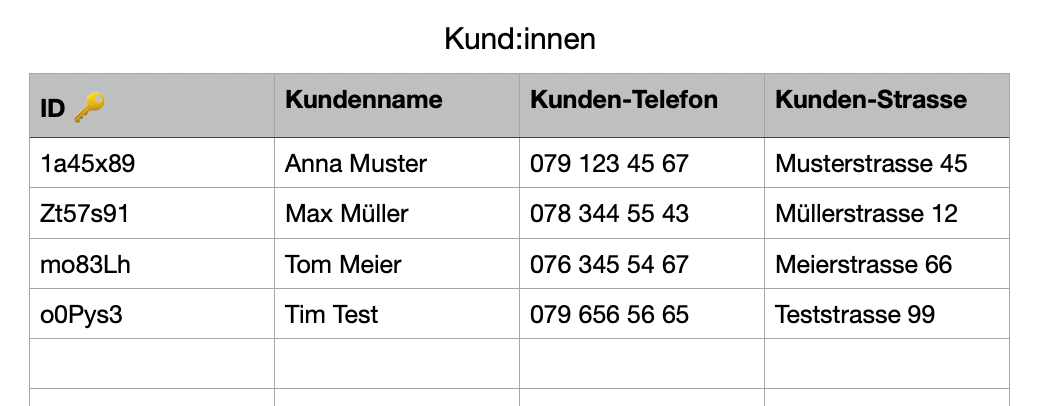
Fremdschlüssel (Foreign Keys) 🔑
Die Aufgabe des Fremdschlüssels ist es, die Beziehungen zwischen den Tabellen festzuhalten. Schau dir noch einmal das Beispiel unserer Strick-Tabelle oben an (mit den zwei Tabellen). Wie wird hier die Beziehung zwischen Bestellungenund Kund:innen festgehalten? Überlege es dir kurz, bevor du weiterliest.
Lösung
Über die Spalte Kund:in in der Tabelle Bestellungen. Wir haben aber schon oben gelesen, dass der Name dafür eigentlich nicht geeignet ist.
Da wir nun aber den Primären Schlüssel ID in der Kund:innen Tabelle haben, können wir diesen als Fremdschlüssel in der Tabelle Bestellungen verwenden:
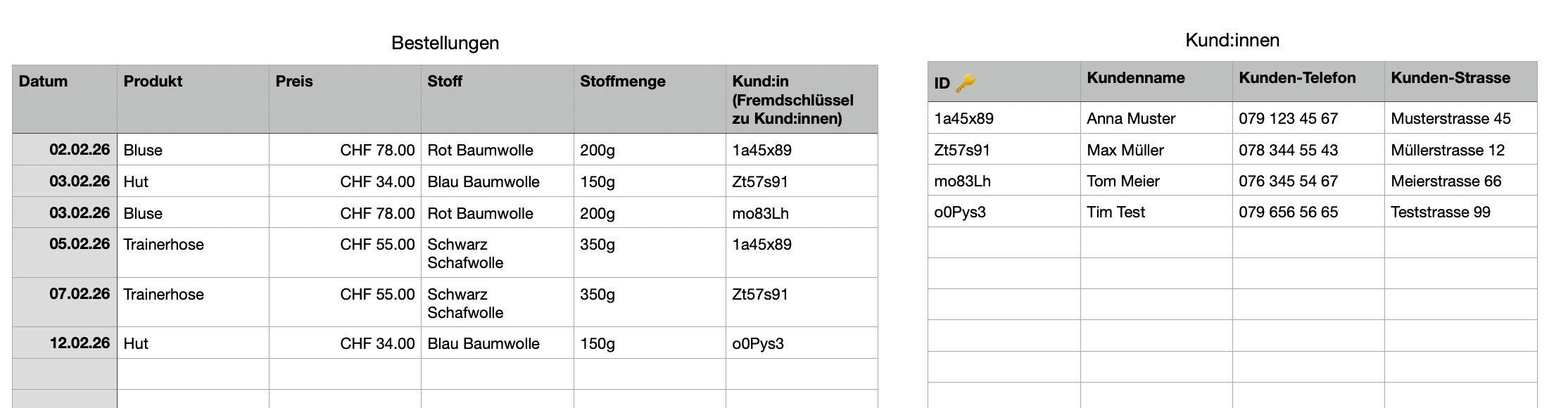
Die Beziehung Bestellung -> Kund:in ist nun eindeutig zuteilbar. Ausserdem haben wir zwei schlankere und einfacher wartbare Tabellen.
Arten von Beziehungen
one to many
Im obigen Beispiel haben wir die wohl gängigste Art von Beziehung zwischen zwei Arten von Werten kennengelernt: one-to-many (Eines-zu-vielen). Etwas einfacher und konkreter ausgedrückt: Ein:e Kund:in hat viele Bestellungen.
Das Wort
vielewird hier allgemein verwendet. Es ist uns in der Planung egal, ob gewisse Kund:innen nur eine Bestellung haben werden. Entscheidend ist, das sie viele haben können.
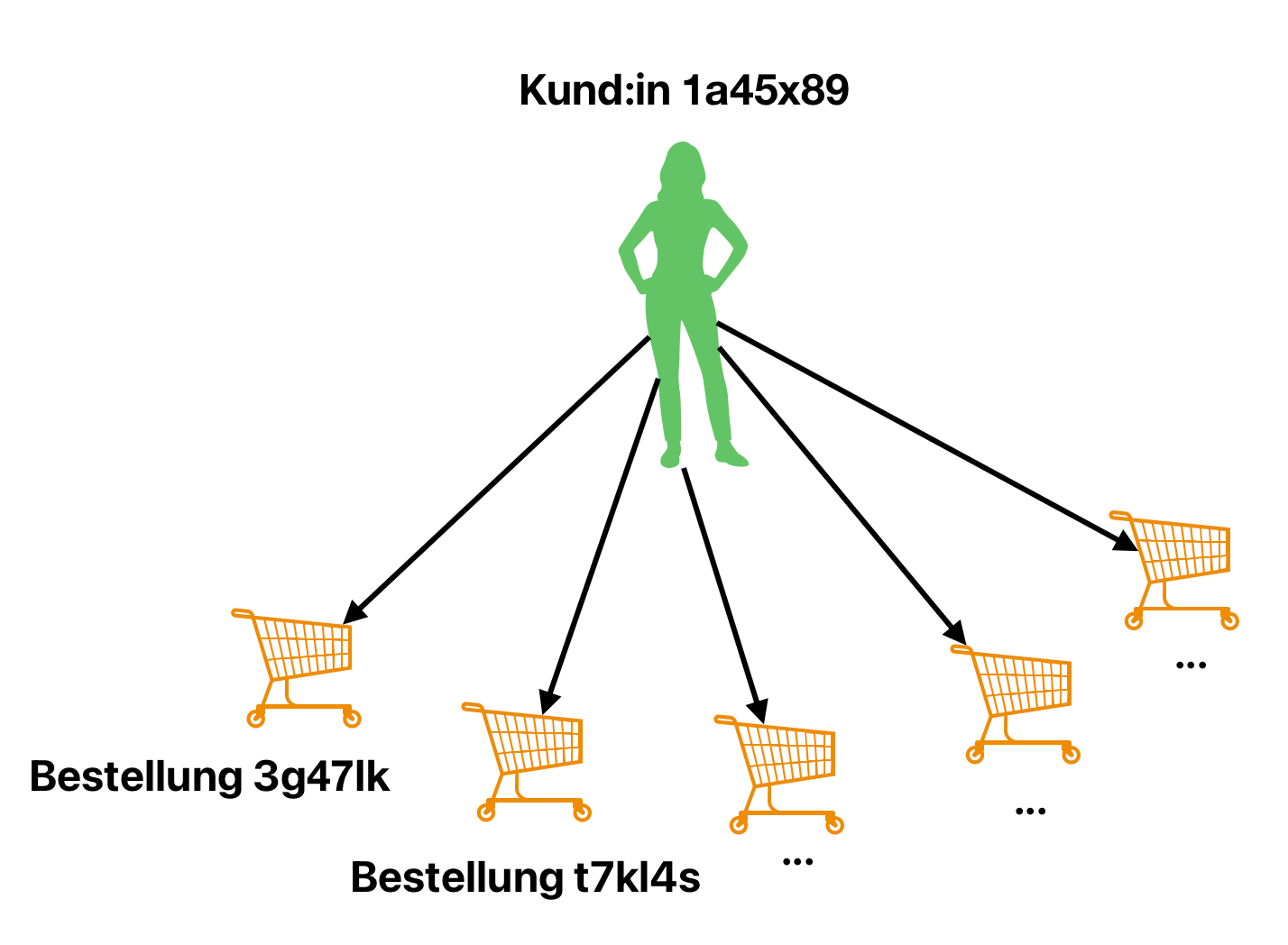
Diese Art von Beziehung wird normalerweise genau so gelöst, wie wir es im obigen Beispiel gemacht haben: In der Tabelle auf der 'viele' Seite (z.B. die Bestellungen) wird ein Fremdschlüssel zu der 'eines' Seite (z.B. Kund:in) eingefügt.
many to many
Die zweite, wichtige Art von Beziehung ist die many-zu-many (viele-zu-vielen) Beziehung. Sie ist im ersten Moment nicht ganz so einleuchtend wie die one-to-many Beziehung, kommt aber auch oft vor. Wir schauen uns das ganze Anhand des Beispiels an. Ich habe unsere Strick-Shop Tabelle noch etwas weiter an das relationale Modell angepasst und eine weitere Tabelle hinzugefügt: Produkte. Sie beinhaltet alle Produkte, die wir im Shop anbieten. Denn diese Informationen waren vorher noch doppelt in der Bestellungen Tabelle vorhanden, was ein Zeichen für schlechtes Design ist.
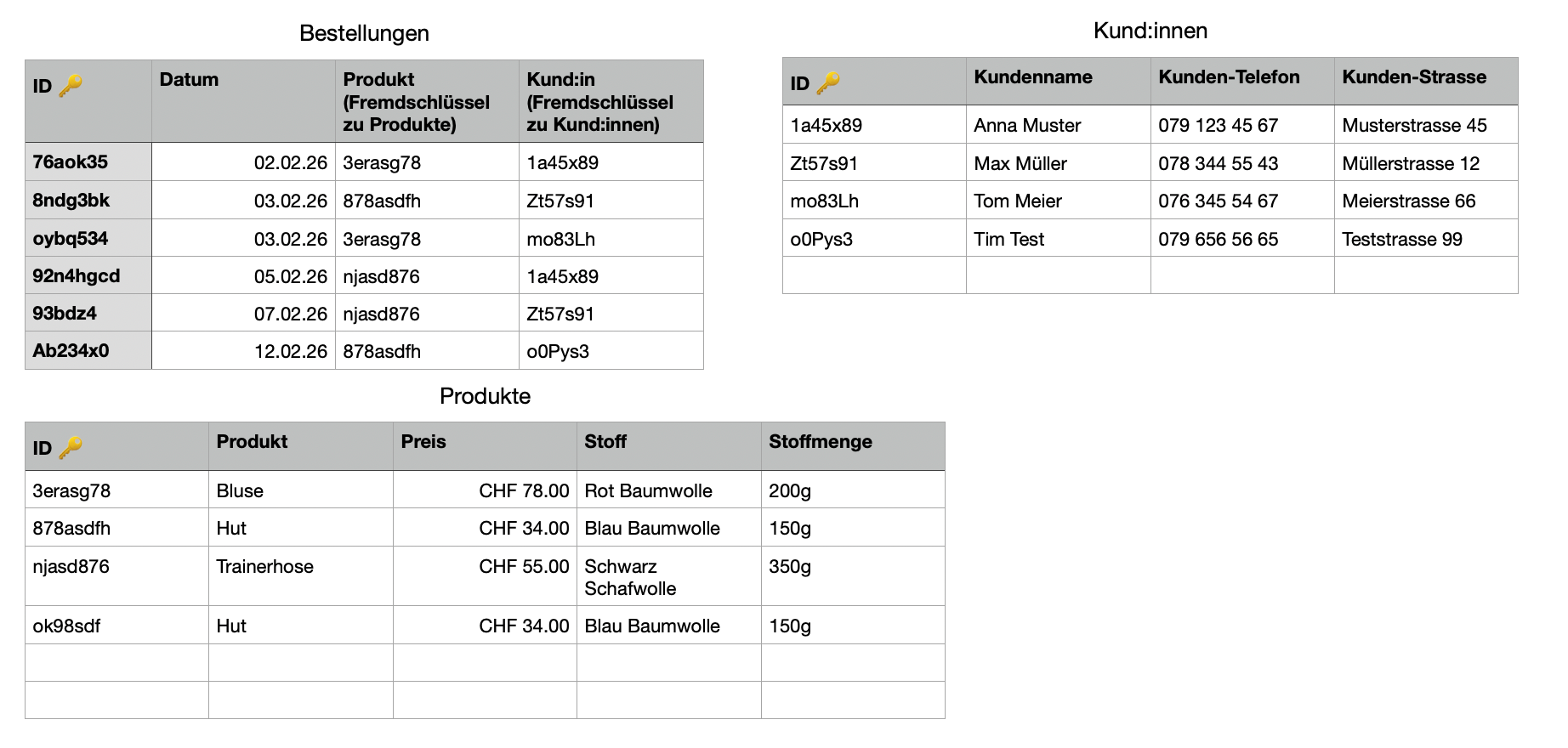
Nun haben wir aber aus Business-Sicht ein grosses Problem, welches sich negativ auf die Verkäufe auswirken wird. Findest du es? Überlege kurz, bevor du weiterliest.
Lösung
Mit diesen Tabellen kann jede Bestellung nur ein Produkt enthalten.
Da wir offensichtlich auch gerne mehrere Produkte in einer Bestellung verkaufen möchten, muss eine Lösung her. Die Antwort ist zum Glück relativ einfach: Noch eine Tabelle! Am einfachsten zeigt sich dies wieder am Beispiel:
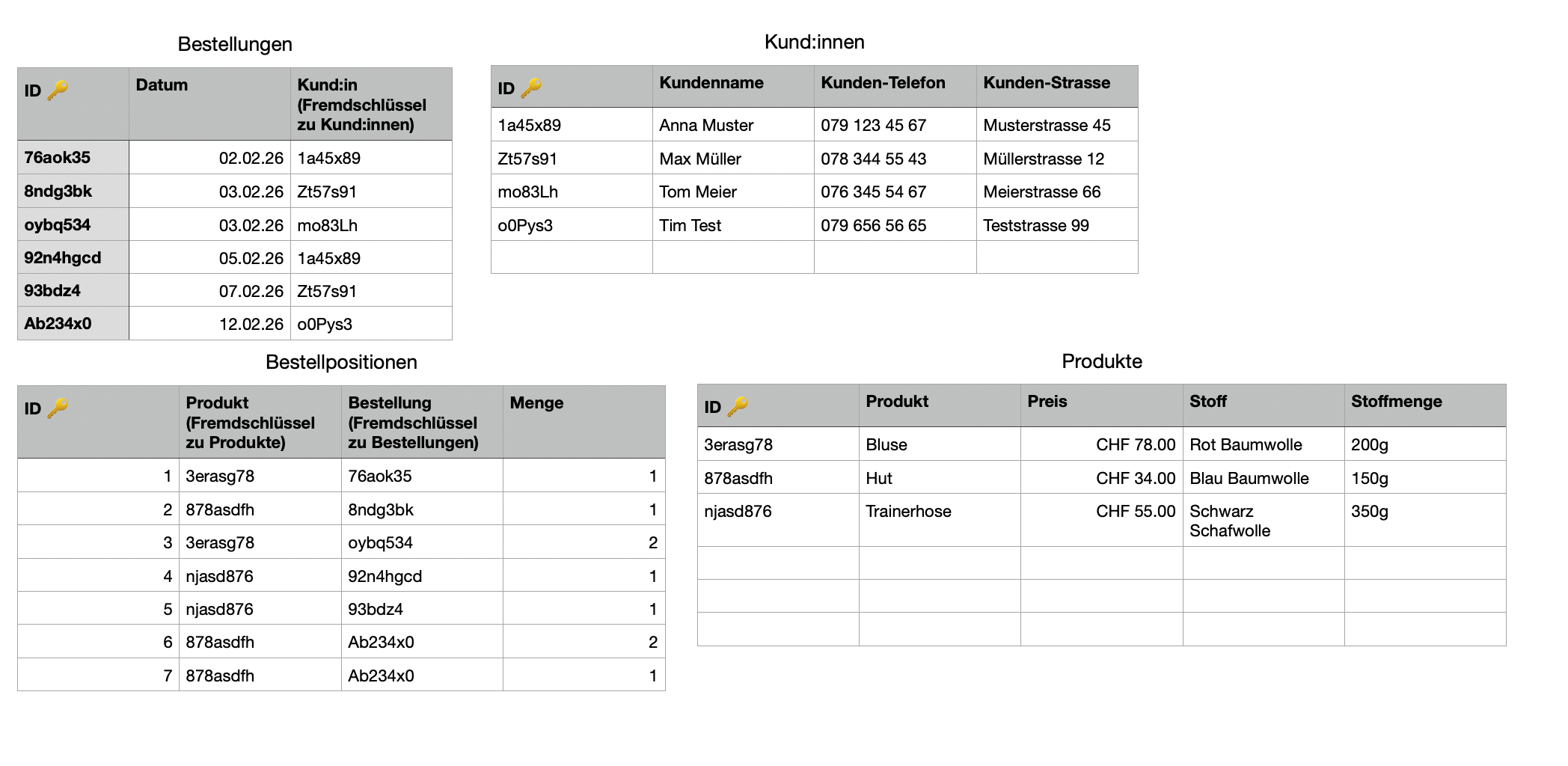
Die Tabelle Bestellpositionen verbindet Bestellungen und Produkte. Eine Bestellung kann mehrere Produkte haben und ein Produkt kann in mehreren Bestellungen vorkommen -> Many to Many.
Im Beispiel habe ich einer Bestellung ein zweites Produkt hinzugefügt. Erkennst du sie?
Diese Art von Tabellen, welche nur dazu da sind um eine many-to-many Beziehung darzustellen, nennt man Verbindungstabelle.
Modellierungstechnik - Entity Relationship Diagramme
Du hast nun hoffentlich eine Vorstellung über die essenziellen Konzepte hinter Datenbanken. Wie bereits erwähnt ist die Gestaltung der Datenbank ein entscheidender Schritt in der Planung eines Informatik-Systems. Lange bevor auch nur eine Zeile Code geschrieben wird, müssen die Informatiker:innen an das Zeichnungs-Board. Der erste Schritt besteht nämlich darin, die Tabellen und die Beziehungen unter den Tabellen in einem Entity-Relationship-Diagramm (kurz ER Diagramm) grafisch festzuhalten. Auch hier starten wir am besten mit einem Beispiel. Das folgende ER-Diagramm stellt unsere Tabellen aus dem Strick-Geschäft dar:
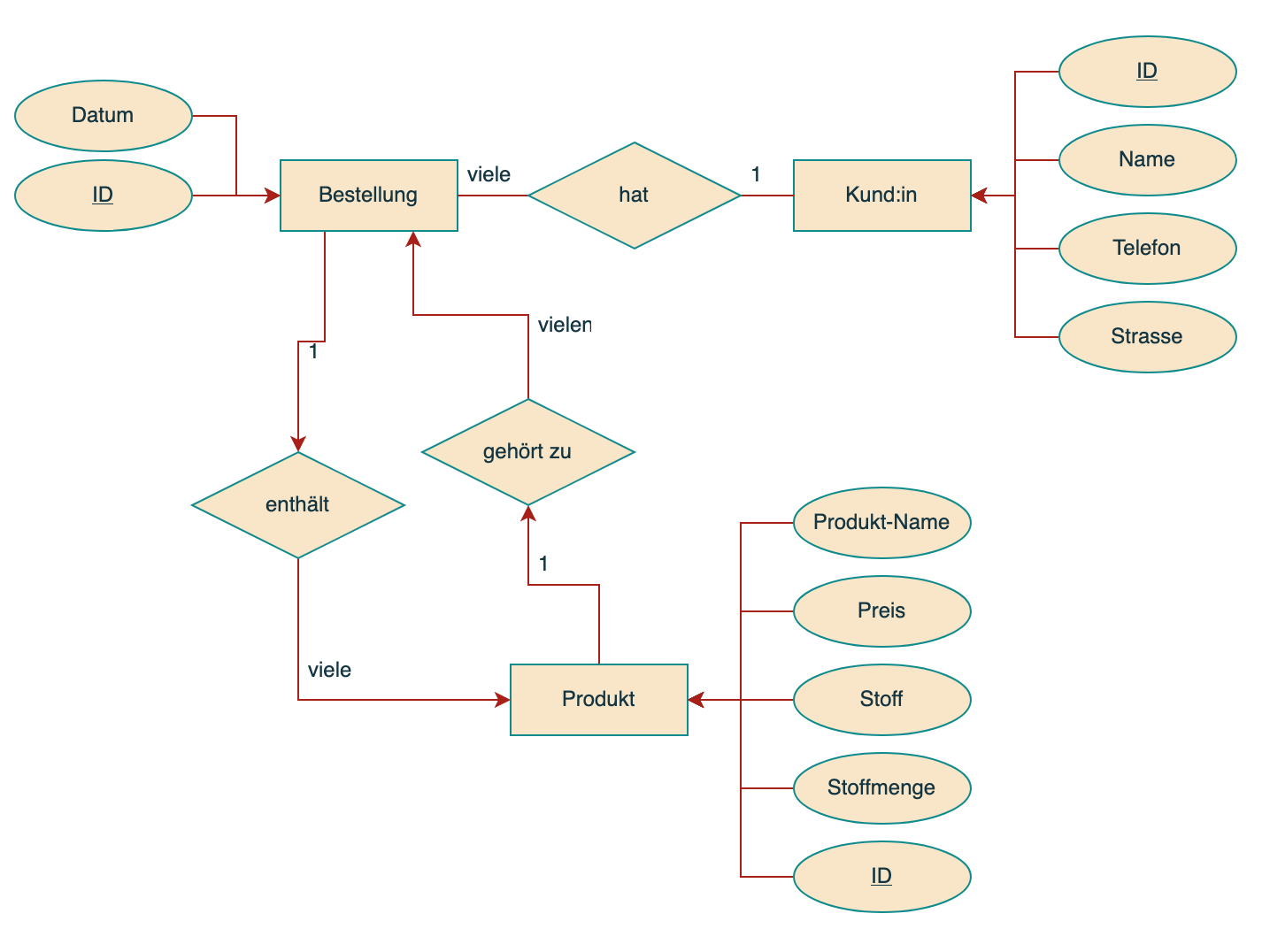
Nimm dir etwas Zeit und schau das Diagramm in Ruhe durch. Es beschreibt die Beziehungen zwischen den Tabellen unseres Geschäfts.
Elemente eines ER Diagramms
Entities - Entitäten - "Dinge"
Entitäten entsprechen den Dingen, die wir darstellen wollen: Produkte, Bestellungen, Kund:innen, usw. Sie werden mit rechteckigen Kästchen dargestellt und meist mit einem klaren Nomen bezeichnet. Normalerweise hat man eine Entität pro Tabelle (ausgenommen von Beziehungstabellen).
Relationships - Beziehungen
Die Beziehungen zwischen den Entitäten werden mit Raute-förmigen Kästchen dargestellt und einem Verb bezeichnet, welches idealerweise die Beziehung zwischen den Entitäten möglichst gut beschreibt. Die Beziehungen werden auf beiden Seiten mit 1 und viele angeschrieben, um die Art der Beziehung klar darzustellen.
Attribute - Eigenschaften
Die ovalen Kästchen stellen die Eigenschaften der Entitäten dar. Diese werden später dann die Spalten der Tabelle sein. Primäre Schlüssel werden durch unterstreichen des Textes gekennzeichnet.
Einfaches Tool für ER Diagramme: draw.io
Hinweis zu Fremdschlüsseln: Diese werden in ER-Diagrammen nicht explizit dargestellt. Darum wird z.B. auch der Fremdschlüssel
Kund:inin der TabelleBestellungennicht als Attribut dargestellt. Durch die Beziehung im ER-Diagramm sollte es klar sein, dass ein Fremdschlüssel notwendig ist.
In der Praxis sollte die Gestaltung des ER-Diagramms viel mehr Zeit in Anspruch nehmen, als die Programmierung der Datenbank. Oder anders ausgedrückt: Wenn die Planung gut gemacht wurde, geht die Programmierung viel schneller. Die Programmierer:innen sollten mit einem guten ER-Diagramm die Datenbank einrichten können ohne irgendetwas über das Geschäft wissen zu müssen.
Vom Diagram zur Datenbank
Wie bereits mehrfach erwähnt wurde, sollte die Planung der Datenbank viel Zeit und Fokus in anspruch nehmen. Während dieser Phase wird mit zukünftigen Nutzer:innen des Systems gesprochen und versucht, möglichst genaue Informationen zu ermitteln für Dokumente, wie z.B. das ER Diagram. Es gibt noch weitere Arten, wie man Pläne für Datenbanken darstellen kann, sie haben aber alle das gleiche Ziel.
Wenn die beschreibenden Dokumente bereit (ER-Diagramm, Tabellen) sind, werden die Informationen an die Entwickler:innen übergeben. Diese erstellen dann (z.B. auf einem Server) eine Datenbank mit den entsprechenden Tabellen.